

信创时代的运维底座:一套平台如何扛起全域监控的重担
![]() 作者:监控易 来源:美信时代
发布时间:2026-04-26
作者:监控易 来源:美信时代
发布时间:2026-04-26
一、运维困境:多工具割裂导致响应滞后
你说现在搞IT运维累不累?真累。我前两天跟一个老朋友吃饭,他在某省属国企做运维主管,酒过三巡就开始吐槽:他们以前用四五套工具管东西——一套看服务器,一套盯网络,一套管数据库,还得靠人工巡检机房。结果呢?告警天天响,真出问题了谁都说不清到底是哪儿炸的。最离谱的一次,线上系统卡了半小时,最后发现是防火墙策略改错了,可那段时间根本没人收到相关告警。
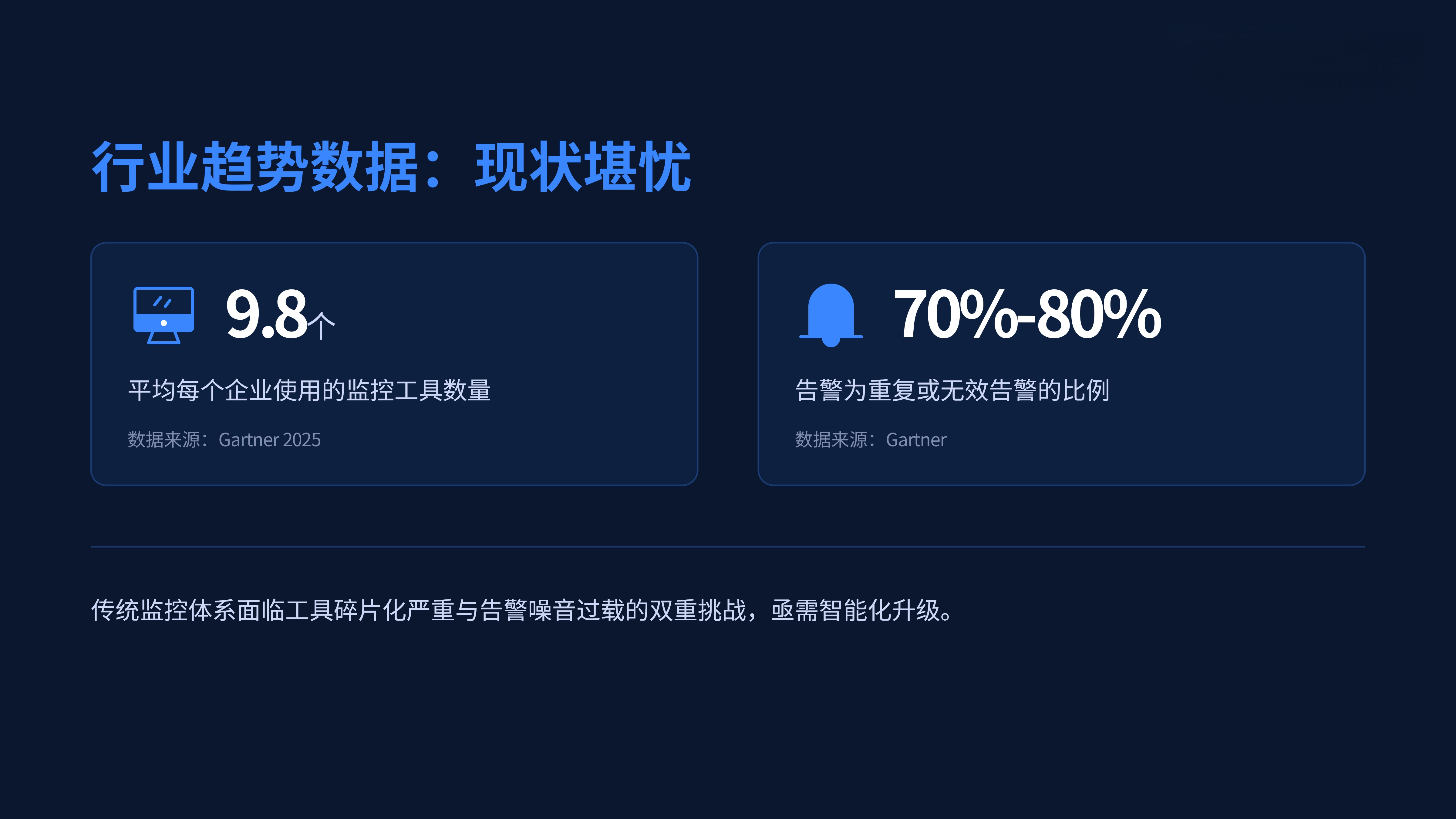
这事儿搁五年前可能还算“常态”,但现在不行了。尤其是这两年信创推得猛,国产芯片、操作系统、数据库铺天盖地换上来,旧那一套拼凑式运维早就玩不转了。不是不想整合,是市面上太多所谓“一体化平台”,看着功能一大堆,其实底层全是外包组件拼的,换个达梦数据库就不认,连个麒麟系统的CPU负载都采不上来。你说气人不气人?
所以现在真正能打的,不是功能多,而是能不能扎扎实实做个可靠的数据基石。就像盖楼,地基打得深,上面才能起高楼。这个地基就是:不管你是飞腾CPU还是鲲鹏主板,不管是统信UOS还是欧拉系统,哪怕是政务专网里那些非标的勘探设备,都得给我稳稳当当把数据掏出来,还不许掉链子。
二、构建可靠运维底座的四大关键技术能力
咱们掰开揉碎看,这事怎么做到的?
首先是协议层必须通吃。你不能只支持SNMPv2,现在信创环境里IPMI、Redfish、SSH密钥登录一堆新老混搭,就连某些特种设备还在用私有Modbus协议。真正厉害的系统,得像章鱼一样伸出触手——Agent轻量部署,非Agent也能穿透采集,连Windows那种编译版本的客户端都给你适配好,内存占不满100MB。这样边远站点的小盒子照样跑得动,边缘设备也不至于成了监控盲区。
然后是数据采集的实时性问题。你想想,传统监控五分钟一轮询,等你发现数据库连接池满了,黄花菜都凉了。现在的路子是啥?秒级轮询+自研时序数据库。比如有些平台能把采集频率压到5秒,配合自家写的Non-SQL数据库,写入效率高出普通MySQL十几倍。这不是炫技,是救命。某电力公司就靠这招,在一次内存缓慢泄漏的过程中提前17分钟预警,抢在业务中断前完成了切换。
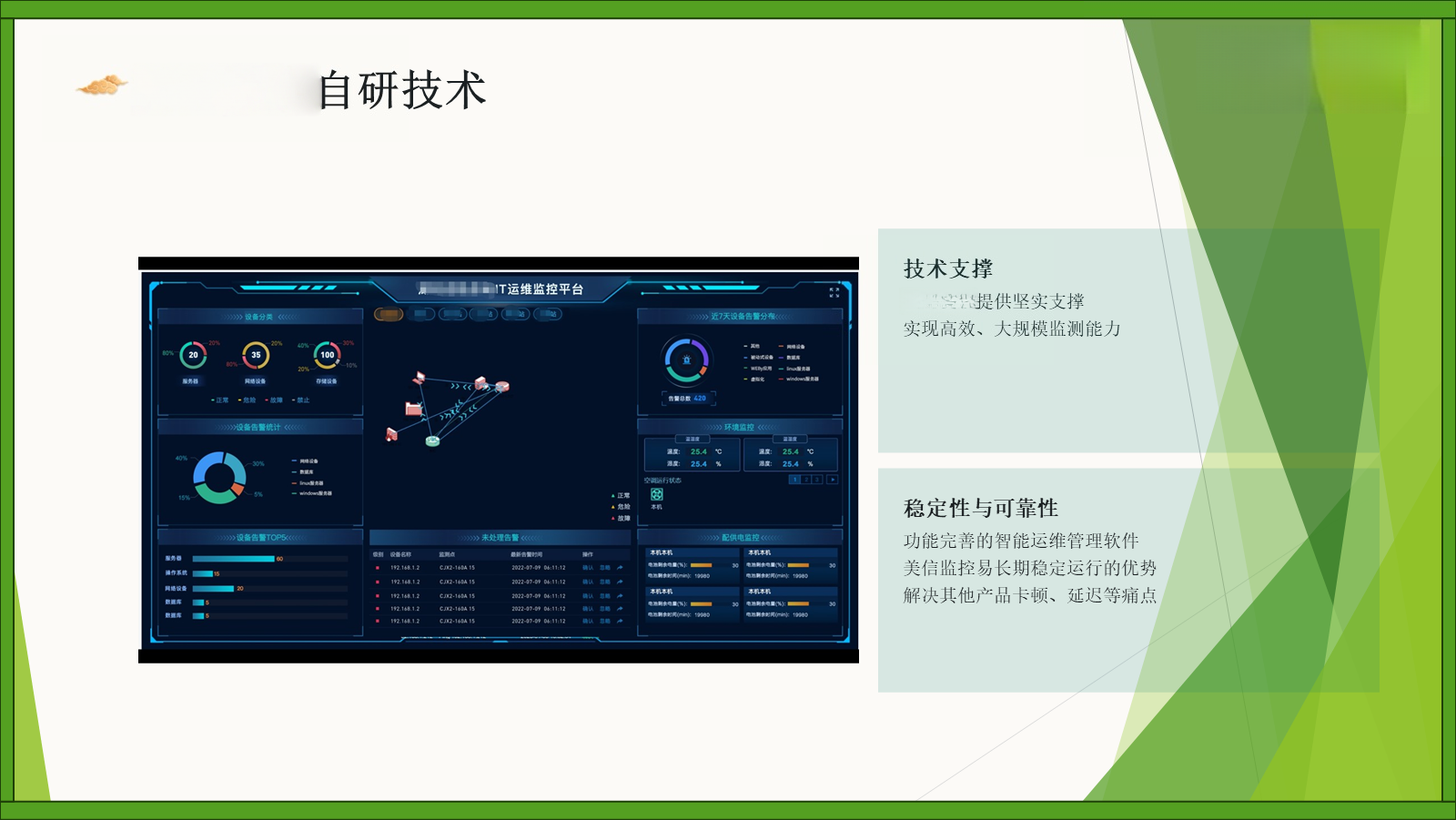
但这还不够。数据拿上来只是第一步,关键是别让人“看不懂”。这时候就得上可视化大杀器了。
比如说那个“链路航线图”,我在一个高速集团见过实操——全国几十个收费站的专线状态,直接叠在中国地图上,哪条链路延迟高了,立马红成一片。运维大哥坐在指挥中心喝着茶,一眼就知道该找哪个区域的同事去查。还有3D机房模型,UPS电池电量、空调风机转动全动态显示,新人来了都不用培训,看动画就知道哪个机柜快过热了。

不过说实话,最让我觉得“卧槽”的,是AI和知识库的联动玩法。
你有没有经历过这种场景:半夜三点告警响了,显示“Oracle表空间不足”,但你上去一看,人家用的是达梦数据库……命名规则不一样嘛!过去的系统傻乎乎报警,现在聪明的已经开始“翻译”了。通过告警映射设置,能把原始代码转成“核心业务数据库剩余容量低于10%”这种人话。更狠的是,一旦触发,自动调用AI知识库,搜历史案例,弹出处理步骤:“立即清理归档日志→执行收缩脚本→通知DBA复查”。新来的小兄弟照着点几下鼠标就能处理,效率翻倍。
当然,光会“看病”还不行,最好还能“算命”。这就是智能预测管理的舞台。用RNN模型跑CPU、内存、磁盘IO的多变量联合预测,准确率能做到九成以上。我看过一个制造企业的例子,系统提前两天预测到某台MES服务器内存将耗尽,运维组趁周末窗口期扩容,整个过程用户无感。这叫什么?这就叫从“救火队员”变成“天气预报员”。
最后说点实在的:这套体系之所以能在信创环境下立得住,归根结底是因为根子是自己的。
你不依赖别人的数据库,不靠开源中间件撑场面,从采集引擎到Web服务全是自研。这意味着两点:第一,安全可控,不怕“卡脖子”;第二,能深度优化。比如针对国产化硬件定制采集逻辑,针对党政机关四级部署架构做数据分级——上级能看到汇总态势,基层单位只能看自己辖区,既满足集中管理,又符合安全边界。
所以说到底,今天的智能运维,拼的不再是功能清单有多长,而是整套技术栈能否沉下去、融进去、跑得稳。当别人还在为兼容某个新国产中间件头疼时,早早就打通全链路的企业已经把精力放在怎么用AI做故障自愈上了。

三、未来方向:从“功能堆砌”到“价值创造”
未来肯定不是人人写脚本、天天盯屏幕的时代了。我们要的,就是一个能扛得住复杂环境、顶得住高并发、看得懂业务影响的“全能管家”。不是替代人,而是让人从繁琐操作里解放出来,去做更有价值的事。
这才是技术该有的样子。

京ICP备09099829号 / 京公网安备:11010702001279 监控易.一体化运维管理软件 © 2007-2025 北京美信时代科技有限公司 版权所有 咨询 Tel : 15652658866 (微信同步) 版本号:1.0 开发者姓名:开发者 隐私协议