

监控易直播演示产品:构建可视、可管、可控的智能网络,从拓扑到流量的精细化运维
![]() 作者:监控易 来源:美信时代
发布时间:2026-06-14
作者:监控易 来源:美信时代
发布时间:2026-06-14
各位同事、各位技术同仁:
大家好!在日常的网络运维工作中,大家是否经常遇到这样的困境:
1. 业务部门反馈说“网络好慢”,可我们登录设备一看,CPU、带宽都正常,问题到底藏在哪里?
2. 没有整理过IP地址清单,需要新增了一台服务器时,随手填了个IP,结果某个系统突然掉线了,一查才发现是IP地址冲突。
3. 更头疼的是,半夜收到告警说核心交换机流量飙到了95%,但谁在用、干什么用,完全是一团迷雾。
这些问题的根源,在于我们对网络的不可见。今天,我想围绕3个关键词,分享我们如何让网络变得“可视、可管、可控”。这四个词就是:拓扑自动发现、网络设备流量分析、IP地址扫描和管理,最后会在介绍我们的专线管理。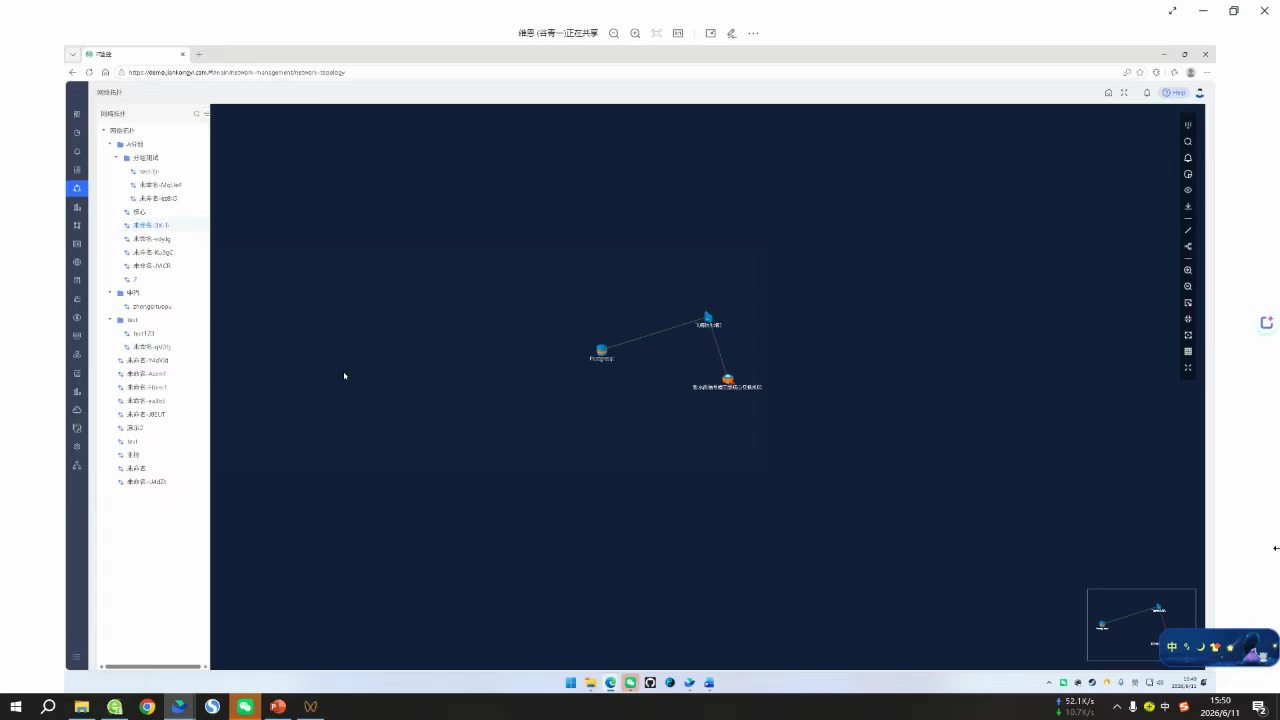
第一部分:拓扑自动发现 —— 让网络地图“活”起来
首先,什么是拓扑自动发现?
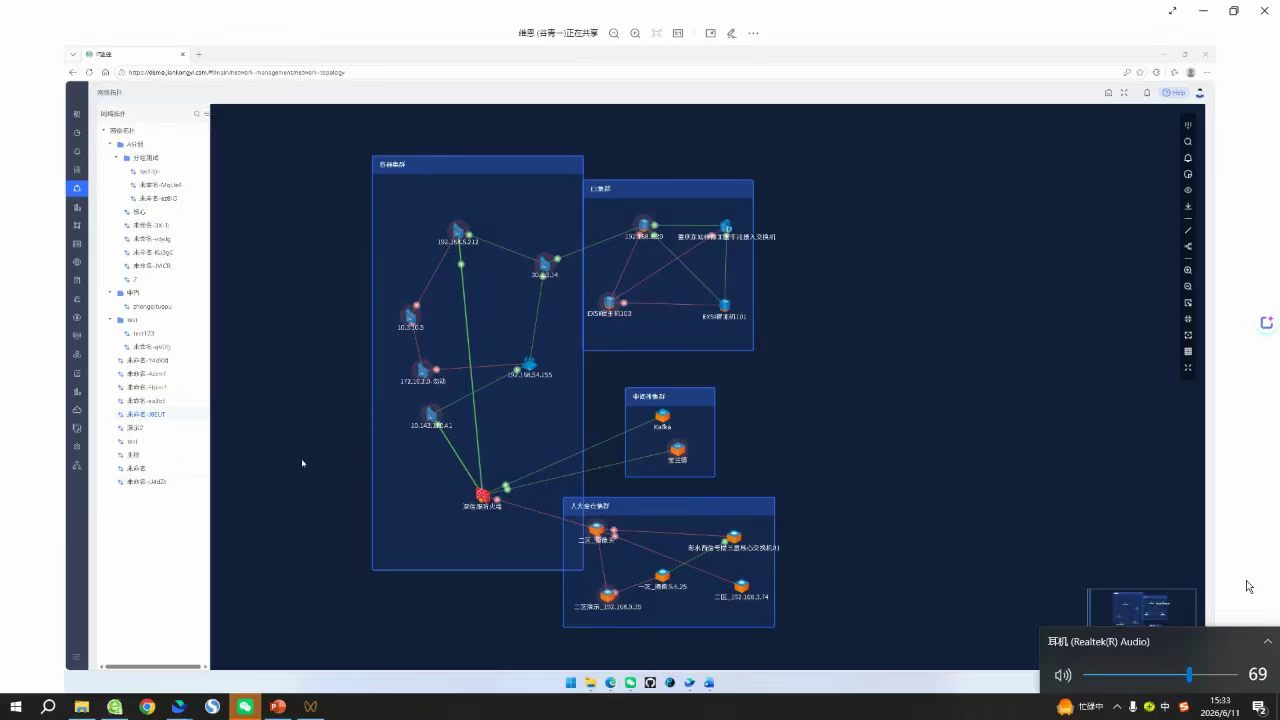
在过去,我们可能靠Visio画图,或者依赖工程师的记忆来维护网络结构。结果一次机房搬迁,发现文档里的链路和实际完全对不上,最后靠着拔线看灯才理清连接关系。但网络是动态的,设备会增减、链路会变化,静态拓扑图很快会变成一张“过期地图”。
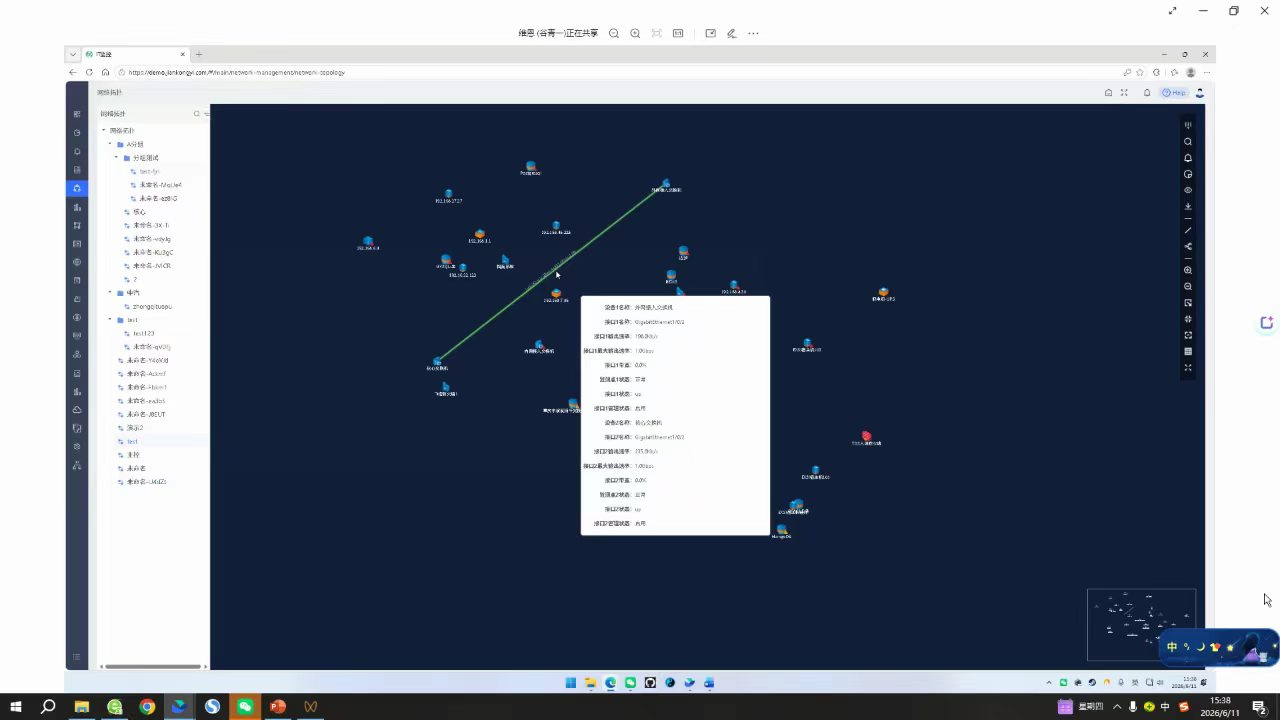
那么拓扑自动发现是怎么工作的呢?它就像是给网络装上了一台实时更新的雷达。它通过SNMP、LLDP或CDP协议,主动去“问”每一台网络设备:你是谁?你连接着谁?你的邻居是什么?一台交换机可能通过LLDP告诉网管系统:“我的端口Gig0/1连着一台路由器,IP是10.0.1.1,我的端口Gig0/2连着一台服务器,MAC地址是xx:xx”。系统把这些信息收集起来,自动绘制出一张动态的网络地图。
有了自动发现,我们能实现:
1. 实时性:网络结构一变化,拓扑图自动更新。当你在机房插上一台新交换机,几分钟后拓扑图上就会多出一个新节点,连带着上下游关系一目了然。
2. 准确性:彻底告别人工维护的错漏。再也不会有“我明明改了配置,为什么拓扑图还是旧的”这种问题了。
3. 快速故障溯源:分支机构突然断网,我们打开拓扑图,能快速发现是上游的一台汇聚交换机宕机,而它的下游连着6个办公室的200多台设备。我们第一时间就知道影响范围,而不是等用户一个个来报修。
一张动态、精准的网络拓扑图,是我们运维工作的“作战指挥地图”。
第二部分:网络设备流量分析 —— 读懂数据的高速公路
有了地图,我们还要知道路上的车流状况。这就引出了第二个主题:网络设备流量分析。
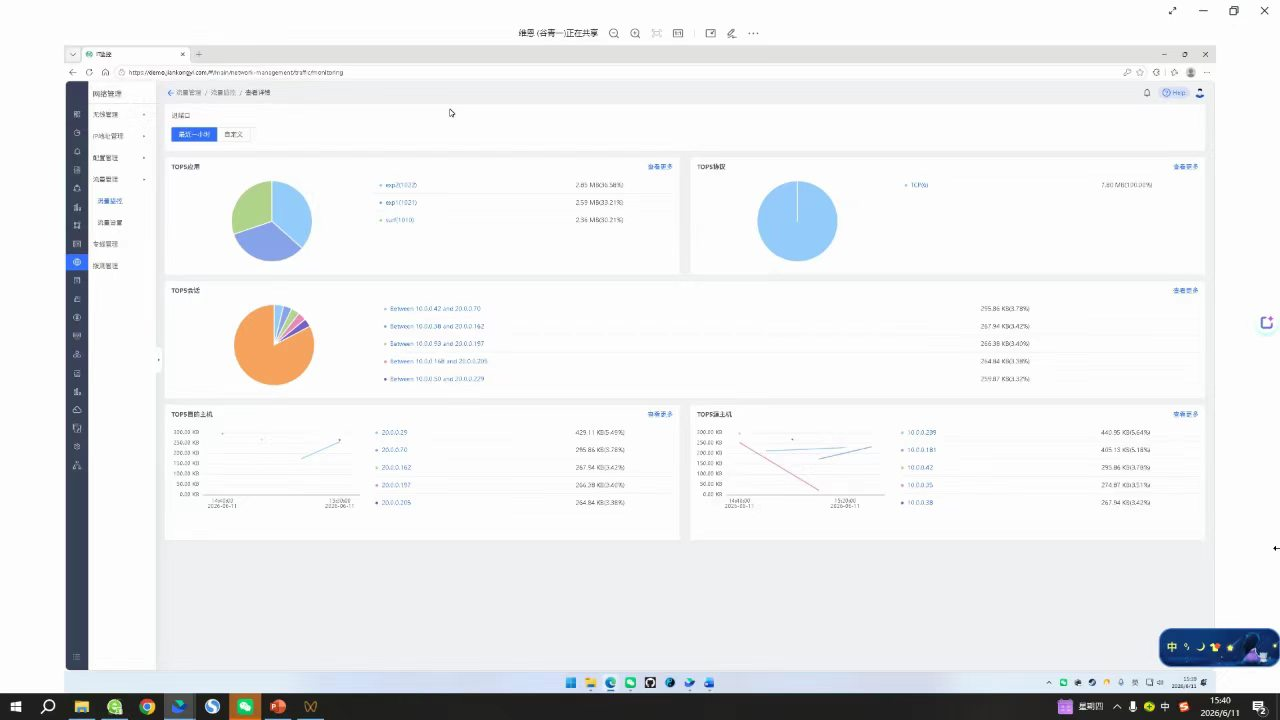
很多时候,用户说“慢”,但我们无法判断是链路拥塞、设备丢包,还是应用本身的问题。带宽用了80%,但这80%里到底有什么?是正常的业务高峰?有人在下载文件?还是中了挖矿病毒?凭感觉去猜,往往会误判。流量分析就是来解决这个问题的。
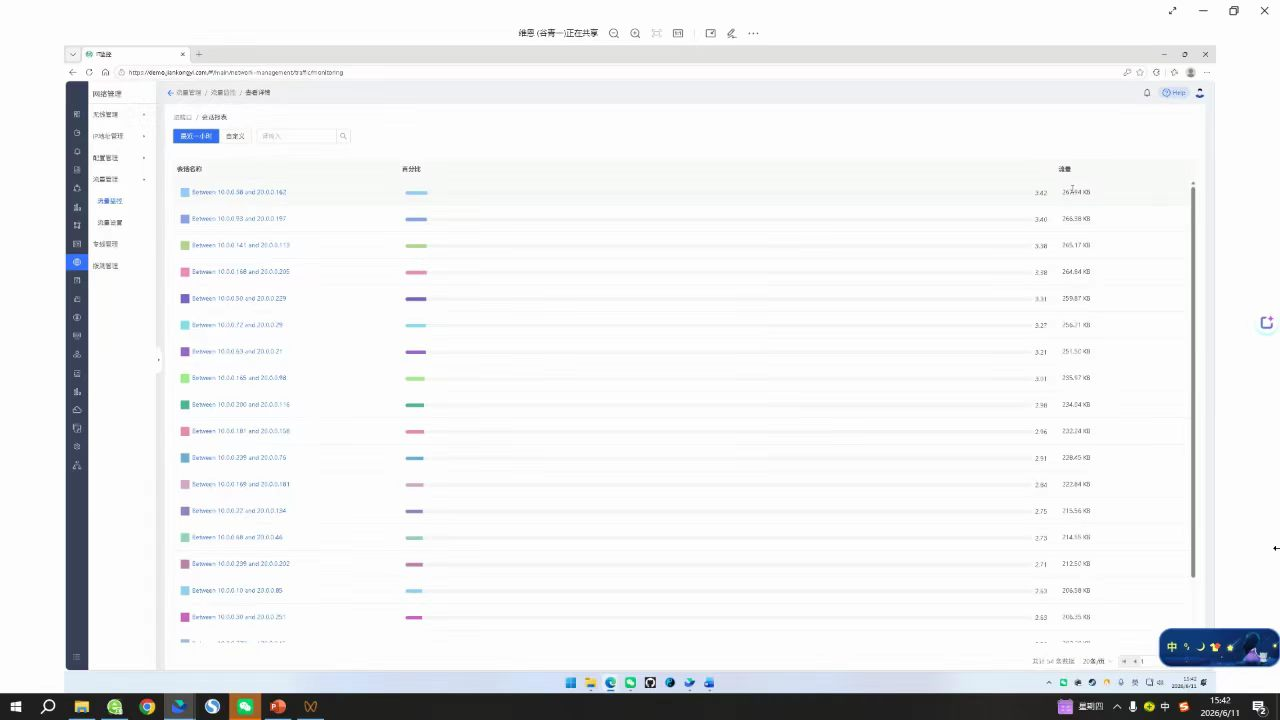
具体怎么做的?我们通过NetFlow、sFlow等技术,采集网络设备经过的每一个数据流的“五元组”(源IP、目的IP、源端口、目的端口、协议),以及流量大小、持续时间等信息。这就像是高速公路上的ETC门架——不抓取你的全部行李,但记录下你的车牌、车型、从哪里来、到哪里去、花了多长时间。这些信息已经足够我们分析问题了。
分析这些数据,我们能回答三个核心问题:
1. 谁在用?哪个部门、哪台主机、哪个用户正在占用带宽?我们可以直接看到,“10.2.3.4这个IP在过去一小时内产生了20GB流量,占用了总带宽的45%”。
2. 做什么?流量是视频会议、文件备份,还是异常攻击?通过端口号和应用识别库,我们能区分出这20GB是Teams视频会议,还是BT下载,抑或是DNS放大攻击。
3. 去哪里?流量是访问内部服务器,还是去往互联网?如果大量流量涌向一个陌生的海外IP,那就要高度警惕了。
第三部分:IP地址扫描和管理 —— 把“门牌号”管起来
最后,我们来聊聊一个最基础却最容易混乱的问题:IP地址管理。
先说一个典型场景:一个中型企业,有500多个IP设备,Excel表格里记录了300多个,剩下的200多个散落在各个工程师的笔记本里、便签纸上、甚至脑子里。新服务器上线,技术部说“好像192.168.1.100没人用”,结果配上去之后,办公室的打印机立刻罢工了——原来那个IP之前就被分配了,只是一直没人更新表格。
我相信很多人都有过类似的经历。这就是IP管理的痛点。解决方案是将主动扫描与制度化管理结合。
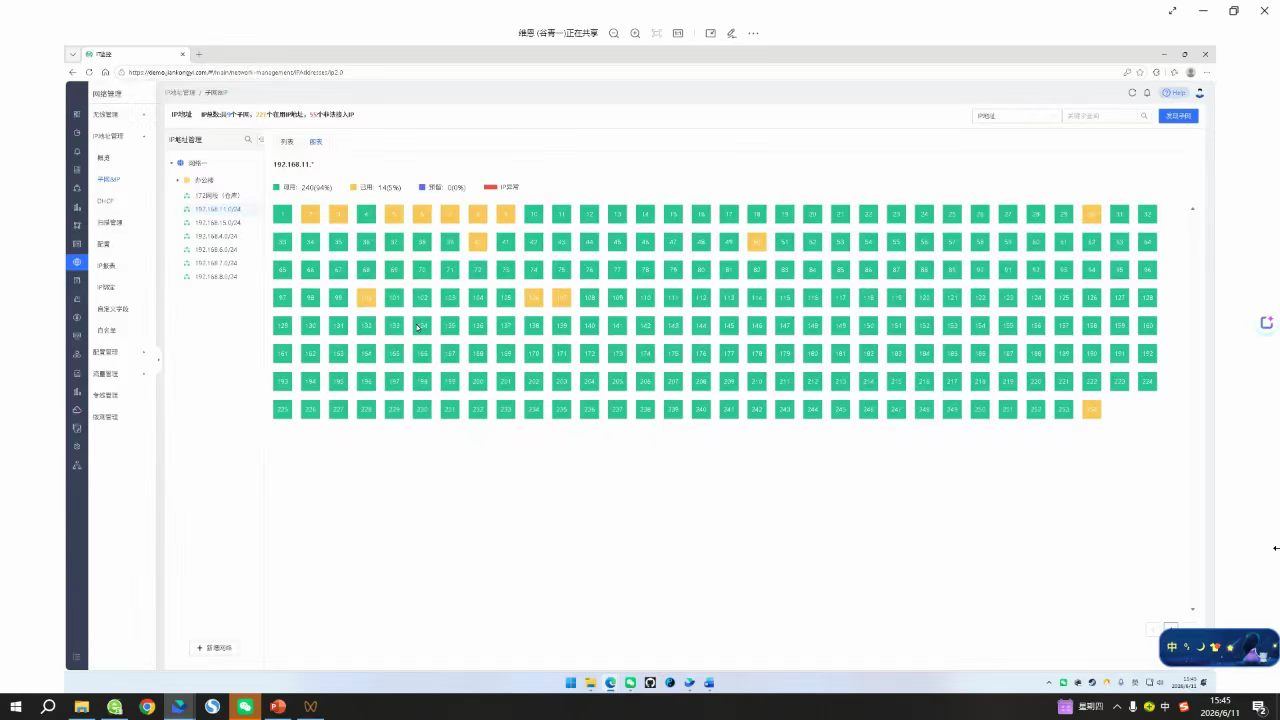
IP地址扫描:网管系统定期通过ICMP(ping)、ARP扫描、SNMP探测等方式,自动扫描全网的IP存活状态。它能实时告诉我们:哪个IP在线,对应的MAC地址是什么,扫描完成之后我们可以通过编辑填写当前IP对应的信息。。
好的IP管理,能让“IP地址”这个最基础的资源,从混乱的“公地悲剧”,变成清晰、有序、可审计的宝贵资产。
第四部分:专线管理 —— 让“黑盒”链路变得透明可控
最后,我想加一个很多人忽略、但恰恰是“花钱最多、出问题最痛”的话题:专线管理。
很多企业都租用运营商的专线,用于连接总部与分公司、连接数据中心与公有云,或者接入第三方合作伙伴。每个月花着几千甚至几万的租金,但我们对这条链路的了解,往往只有一个带宽数字,和一张运营商的“开工单”。一旦业务说“连不上”,我们怎么判断是本地设备坏了、对端设备挂了,还是运营商的专线中间断了?更头疼的是,专线“偶尔丢包、时延忽高忽低”,这种软故障最难排查,业务部门投诉“网络不稳定”,我们却拿不出数据证明是运营商的问题还是自己的问题。
专线管理的核心目标,就是让这条“黑盒”链路变得透明、可量化、可主动告警。具体怎么做?我们靠两个技术手段:代理Ping和SNMP深度监控。
第一,代理Ping——解决“通不通”的问题。
我们无法直接登录到运营商的传输设备去Ping对端,但我们可以在本端网络设备(比如路由器或三层交换机)上配置代理Ping。简单来说,就是让本端设备主动向对端的网关IP或关键设备IP发送ICMP探测包,并且连续发送多次(比如每30秒发5个)。如果连续3次探测都超时,系统就判定专线中断,立刻发出告警。
代理Ping比单纯看端口状态要聪明得多。端口状态只告诉你“本端设备的接口灯亮不亮”,但如果运营商的中间链路断了,本端端口可能依然是UP状态(因为连接的是运营商的光电转换器),可实际业务已经不通了。代理Ping直接测试端到端的可达性,能真正反映业务感知。
第二,SNMP监控——解决“质量怎么样”的问题。
Ping只能判断通断,但专线质量好不好,还需要更精细的数据。我们通过SNMP协议,定期采集专线两端网络设备上对应接口的MIB信息。重点关注四个核心指标:
1. 接口带宽利用率(in/out的速率):是否经常接近专线带宽上限,导致拥塞丢包。
2. 丢包计数(ifInDiscards、ifOutDiscards、ifInErrors):接口丢包数量持续增长,说明链路质量差或者设备性能不足。
3. 错包计数(ifInErrors、CRC校验错误):大量错包往往意味着物理线路问题(光衰、电磁干扰),这是联系运营商换纤的有力证据。
4. 广播包比例(如果异常升高,可能是有广播风暴或环路)。
更进一步,代理Ping和SNMP可以联动拓扑:当一条专线中断时,系统不仅发出告警,还会在拓扑图上把这条专线的连线变成红色,同时高亮显示受影响的下游设备和业务。如果是备用专线,还能自动触发路由切换,真正实现“故障自愈”。
所以,专线管理不是玄学,它就是靠代理Ping测通断、靠SNMP读质量。这两者结合,再加上历史数据的趋势分析,我们就能做到:专线还没断就提前预警(比如丢包率持续爬升),断了之后快速定界(本地、对端还是运营商),并且有理有据地和运营商沟通。花着专线的钱,不能再受“黑盒”的气。
结尾:四位一体,智能运维
总结一下,我们今天讲了四个核心能力:
- 拓扑自动发现,解决了“设备怎么连”的问题。
- 网络设备流量分析,解决了“线路跑什么”的问题。
- IP地址扫描和管理,解决了“资源谁在用”的问题。
- 专线管理(代理Ping + SNMP监控),解决了“跨域链路通不通、质量好不好”的问题。
这四者不是孤立的,而是一张完整的网络运维拼图。拓扑给你全局视野,流量给你深度洞察,IP管理给你精准定位,专线管理给你跨域触角。当它们协同工作时,一个典型的故障排查场景会变成这样:用户说“北京到上海的业务很慢”——你打开流量分析,发现专线利用率正常但丢包率高;点击丢包曲线,系统关联到专线拓扑图,显示这条专线两端的路由器和接口;进一步查看SNMP历史,发现CRC错包从昨天开始增多;同时,IP管理告诉你受影响的业务IP属于财务系统,影响范围明确;最后,你导出数据报告,直接提交给运营商要求修复。整个过程从小时级缩短到分钟级。
网络运维的终极目标,不是修理故障,而是让故障发生之前就被看见。拓扑、流量、IP、专线——这四个维度构建起来,我们才能真正告别“救火式”运维,迈向主动式、预防式、可解释的智能运维新时代。
谢谢大家!
上一篇: 直播回放:监控易一体化运维平台,信创国产化能力介绍
下一篇: 监控易直播回放:网络运维“体检季”

京ICP备09099829号 / 京公网安备:11010702001279 监控易.一体化运维管理软件 © 2007-2025 北京美信时代科技有限公司 版权所有 咨询 Tel : 15652658866 (微信同步) 版本号:1.0 开发者姓名:开发者 隐私协议